Задание состоит из двух частей, первая из которых обязательна для выполнения, вторую необходимо выполнить для получения отличной оценки. Выполнение обеих частей сводится к созданию односвязного списка и реализации методов добавления элементов в этот список. Срок сдачи задания — 25 сентября.
Односвязным списком называется структура данных, построенная следующим образом:
typedef struct _s {
int data;
struct _s *next;
} s;
s *head = 0;
В переменной head хранится 0 (список пуст) либо указатель на первый элемент
списка. Таким образом, список представляет из себя структуру следующего вида:
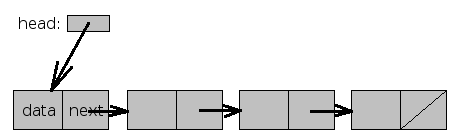
Добавление элемента в начало списка производится следующим образом:
s *p = (s *)malloc(sizeof(s));
/* выделение памяти под новый элемент списка */
p->data = 7;
/* присваиваем значение полю данных */
p->next = head;
/* следующий элемент — тот, который ранее был первым, либо 0, если список был пуст */
head = p;
/* теперь наш добавленный элемент — первый */
Для добавления элемента в середину списка необходимо иметь указатель на предыдущий
элемент. Обозначив его через q, получаем следующий код:
s *p = (s *)malloc(sizeof(s));
/* выделение памяти под новый элемент списка */
p->data = 7;
/* присваиваем значение полю данных */
p->next = q->next;
/* следующий элемент — тот, который ранее следовал за q (возможно, 0) */
q->next = p;
/* теперь наш новый элемент следует за q */
Для поиска элемента в списке необходимо обойти список в цикле, например, так:
p = head;
while (p) {
if (p->data == 7) {
/* сделать необходимые действия */
}
p = p->next;
/* переход на следующий элемент */
}
Второй вариант — аналогичный, но более короткий:
for (p = head; p; p = p->next) {
if (p->data == 7) {
/* сделать необходимые действия */
}
}
В обоих случаях переменная p имеет тип s * и является аналогом
параметра цикла в обычном понимании.
Для удаления списка и освобождения памяти можно использовать следующий код:
while (head) {
/* пока список не пуст */
p = head->next;
/* запомнили следующий элемент */
free(head);
/* удалили первый элемент */
head = p;
/* теперь первым является тот, который был следующим */
}
Во входном файле input.txt в первой строке находится количество чисел N,
в следующих N строках находятся целые числа (тип int) по одному в строке.
Написать две программы, которые выводят в выходной файл output.txt: первая — числа,
отсортированные по возрастанию, вторая — числа, отсортированные по возрастанию без повторений.
Ввод: input.txt
7
|
Вывод 1: output.txt
1 2 2 3 3 4 5
|
Вывод 2: output.txt
1 2 3 4 5
|
Хэш-таблицей называется структура данных, для поиска в которой от ключа вычисляется некоторая функция («хэш-функция»), которая указывает расположения ключа в памяти.
Целью задания является реализация системы хранения переменных и значений. Именем переменной
(ключом) является строка размером до 5 символов, значением — целое число.
Введем соответствующий тип данных. Поле next предназначено для создания односвязного списка:
typedef struct _variable {
char name[6];
int value;
struct _variable *next;
} variable;
Будем считать, что количество различных переменных ограничено 1000. Создадим массив из
2000 (в 2 раза больший) указателей на тип variable. Позаботьтесь о заполнении
массива нулями (это будет сделано автоматически, если массив задан вне какой-либо функции).
#define SIZE 2000
variable *table[SIZE];
Создадим функцию, которая по имени переменной будет возвращать значение от 0 до 1999. Например, как показано ниже (этот вариант — далеко не самый лучший):
unsigned int RND[5] = { 3, 11051, 511, 2047, 29 }; /* абсолютно произвольные числа */
unsigned int hash(char *s)
{
unsigned int res = 0;
for (int i = 0; s[i]; i++) {
res += s[i] * RND[i % 5];
res %= SIZE;
}
return (res);
}
Ясно, что одно и то же имя переменной будет всегда иметь один и тот же код, возвращаемый функцией hash.
В то же время, несколько переменных могут иметь одинаковый код.
Значением элемента table[i] будет являться как раз список переменных, имена которых имеют код
i.
Теперь, если необходимо найти в таблице переменную с именем s, будем
смотреть список, началом (головой) которого является table[hash(s)].
Например, чтобы узнать значение переменной "test", используем следующий код:
int c = hash("test");
variable *p = table[c];
while (p) {
if (!strcmp(p->name, "test")) {
/* нашли; p->value — искомое значение */
break;
}
p = p->next;
}
Во входном файле input.txt в первой строке находится количество записей N,
в следующих N строках находятся записи вида имя значение, причем имена могут
повторяться. В файл output.txt выдать итоговые значения всех переменных в произвольном
порядке.
Ввод: input.txt
5
|
Вывод: output.txt
a 15
|